The metaverse is a network of always-on virtual environments in which many people can interact with one another and digital objects while operating virtual representations – or avatars – of themselves. Think of a combination of immersive virtual reality, a massively multiplayer online role-playing game and the web.
The metaverse is a concept from science fiction that many people in the technology industry envision as the successor to today’s internet. It’s only a vision at this point, but technology companies like Facebook are aiming to make it the setting for many online activities, including work, play, studying and shopping. Facebook is so sold on the concept that it is renaming itself Meta to highlight its push to dominate the metaverse.
The best-selling science fiction novel ‘Snow Crash’ gave the world the word ‘metaverse.’RA.AZ/Flickr, CC BY
Metaverse is a portmanteau of meta, meaning transcendent, and verse, from universe. Sci-fi novelist Neal Stephenson coined the term in his 1992 novel “Snow Crash” to describe the virtual world in which the protagonist, Hiro Protagonist, socializes, shops and vanquishes real-world enemies through his avatar. The concept predates “Snow Crash” and was popularized as “cyberspace” in William Gibson’s groundbreaking 1984 novel “Neuromancer.”
There are three key aspects of the metaverse: presence, interoperability and standardization.
Presence is the feeling of actually being in a virtual space, with virtual others. Decades of research have shown that this sense of embodiment improves the quality of online interactions. This sense of presence is achieved through virtual reality technologies such as head-mounted displays.
Interoperability means being able to seamlessly travel between virtual spaces with the same virtual assets, such as avatars and digital items. ReadyPlayerMe allows people to create an avatar that they can use in hundreds of different virtual worlds, including in Zoom meetings through apps like Animaze. Meanwhile, blockchain technologies such as cryptocurrencies and nonfungible tokens facilitate the transfer of digital goods across virtual borders.
Standardization is what enables interoperability of platforms and services across the metaverse. As with all mass-media technologies – from the printing press to texting – common technological standards are essential for widespread adoption. International organizations such as the Open Metaverse Interoperability Group define these standards.
Why the metaverse matters
If the metaverse does become the successor to the internet, who builds it, and how, is extremely important to the future of the economy and society as a whole. Facebook is aiming to play a leading role in shaping the metaverse, in part by investing heavily in virtual reality. Facebook CEO Mark Zuckerberg explained in an interview his view that the metaverse spans nonimmersive platforms like today’s social media as well as immersive 3D media technologies such as virtual reality, and that it will be for work as well as play.
Hollywood has embraced the metaverse in movies like ‘Ready Player One.’
The metaverse might one day resemble the flashy fictional Oasis of Ernest Cline’s “Ready Player One,” but until then you can turn to games like Fortnite and Roblox, virtual reality social media platforms like VRChat and AltspaceVR, and virtual work environments like Immersed for a taste of the immersive and connected metaverse experience. As these siloed spaces converge and become increasingly interoperable, watch for a truly singular metaverse to emerge.
This article has been updated to include Facebook’s announcement on Oct. 28, 2021 that it is renaming itself Meta.
Haugen was the primary source for a Wall Street Journal exposé on the company. She called Facebook’s algorithms dangerous, said Facebook executives were aware of the threat but put profits before people, and called on Congress to regulate the company.
Social media platforms rely heavily on people’s behavior to decide on the content that you see. In particular, they watch for content that people respond to or “engage” with by liking, commenting and sharing. Troll farms, organizations that spread provocative content, exploit this by copying high-engagement content and posting it as their own, which helps them reach a wide audience.
As a computer scientist who studies the ways large numbers of people interact using technology, I understand the logic of using the wisdom of the crowds in these algorithms. I also see substantial pitfalls in how the social media companies do so in practice.
From lions on the savanna to likes on Facebook
The concept of the wisdom of crowds assumes that using signals from others’ actions, opinions and preferences as a guide will lead to sound decisions. For example, collective predictions are normally more accurate than individual ones. Collective intelligence is used to predict financial markets, sports, elections and even disease outbreaks.
Throughout millions of years of evolution, these principles have been coded into the human brain in the form of cognitive biases that come with names like familiarity, mere exposure and bandwagon effect. If everyone starts running, you should also start running; maybe someone saw a lion coming and running could save your life. You may not know why, but it’s wiser to ask questions later.
Your brain picks up clues from the environment – including your peers – and uses simple rules to quickly translate those signals into decisions: Go with the winner, follow the majority, copy your neighbor. These rules work remarkably well in typical situations because they are based on sound assumptions. For example, they assume that people often act rationally, it is unlikely that many are wrong, the past predicts the future, and so on.
Technology allows people to access signals from much larger numbers of other people, most of whom they do not know. Artificial intelligence applications make heavy use of these popularity or “engagement” signals, from selecting search engine results to recommending music and videos, and from suggesting friends to ranking posts on news feeds.
Not everything viral deserves to be
Our research shows that virtually all web technology platforms, such as social media and news recommendation systems, have a strong popularity bias. When applications are driven by cues like engagement rather than explicit search engine queries, popularity bias can lead to harmful unintended consequences.
Social media like Facebook, Instagram, Twitter, YouTube and TikTok rely heavily on AI algorithms to rank and recommend content. These algorithms take as input what you like, comment on and share – in other words, content you engage with. The goal of the algorithms is to maximize engagement by finding out what people like and ranking it at the top of their feeds.
A primer on the Facebook algorithm.
On the surface this seems reasonable. If people like credible news, expert opinions and fun videos, these algorithms should identify such high-quality content. But the wisdom of the crowds makes a key assumption here: that recommending what is popular will help high-quality content “bubble up.”
We tested this assumption by studying an algorithm that ranks items using a mix of quality and popularity. We found that in general, popularity bias is more likely to lower the overall quality of content. The reason is that engagement is not a reliable indicator of quality when few people have been exposed to an item. In these cases, engagement generates a noisy signal, and the algorithm is likely to amplify this initial noise. Once the popularity of a low-quality item is large enough, it will keep getting amplified.
Algorithms aren’t the only thing affected by engagement bias – it can affect people too. Evidence shows that information is transmitted via “complex contagion,” meaning the more times people are exposed to an idea online, the more likely they are to adopt and reshare it. When social media tells people an item is going viral, their cognitive biases kick in and translate into the irresistible urge to pay attention to it and share it.
Not-so-wise crowds
We recently ran an experiment using a news literacy app called Fakey. It is a game developed by our lab that simulates a news feed like those of Facebook and Twitter. Players see a mix of current articles from fake news, junk science, hyperpartisan and conspiratorial sources, as well as mainstream sources. They get points for sharing or liking news from reliable sources and for flagging low-credibility articles for fact-checking.
We found that players are more likely to like or share and less likely to flag articles from low-credibility sources when players can see that many other users have engaged with those articles. Exposure to the engagement metrics thus creates a vulnerability.
The wisdom of the crowds fails because it is built on the false assumption that the crowd is made up of diverse, independent sources. There may be several reasons this is not the case.
First, because of people’s tendency to associate with similar people, their online neighborhoods are not very diverse. The ease with which social media users can unfriend those with whom they disagree pushes people into homogeneous communities, often referred to as echo chambers.
Second, because many people’s friends are friends of one another, they influence one another. A famous experiment demonstrated that knowing what music your friends like affects your own stated preferences. Your social desire to conform distorts your independent judgment.
Third, popularity signals can be gamed. Over the years, search engines have developed sophisticated techniques to counter so-called “link farms” and other schemes to manipulate search algorithms. Social media platforms, on the other hand, are just beginning to learn about their own vulnerabilities.
A different, preventive approach would be to add friction. In other words, to slow down the process of spreading information. High-frequency behaviors such as automated liking and sharing could be inhibited by CAPTCHA tests, which require a human to respond, or fees. Not only would this decrease opportunities for manipulation, but with less information people would be able to pay more attention to what they see. It would leave less room for engagement bias to affect people’s decisions.
It would also help if social media companies adjusted their algorithms to rely less on engagement signals and more on quality signals to determine the content they serve you. Perhaps the whistleblower revelations will provide the necessary impetus.
An internal Facebook report found that the social media platform’s algorithms – the rules its computers follow in deciding the content that you see – enabled disinformation campaigns based in Eastern Europe to reach nearly half of all Americans in the run-up to the 2020 presidential election, according to a report in Technology Review.
The campaigns produced the most popular pages for Christian and Black American content, and overall reached 140 million U.S. users per month. Seventy-five percent of the people exposed to the content hadn’t followed any of the pages. People saw the content because Facebook’s content-recommendation system put it into their news feeds.
Social media platforms rely heavily on people’s behavior to decide on the content that you see. In particular, they watch for content that people respond to or “engage” with by liking, commenting and sharing. Troll farms, organizations that spread provocative content, exploit this by copying high-engagement content and posting it as their own.
As a computer scientist who studies the ways large numbers of people interact using technology, I understand the logic of using the wisdom of the crowds in these algorithms. I also see substantial pitfalls in how the social media companies do so in practice.
From lions on the savanna to likes on Facebook
The concept of the wisdom of crowds assumes that using signals from others’ actions, opinions and preferences as a guide will lead to sound decisions. For example, collective predictions are normally more accurate than individual ones. Collective intelligence is used to predict financial markets, sports, elections and even disease outbreaks.
Throughout millions of years of evolution, these principles have been coded into the human brain in the form of cognitive biases that come with names like familiarity, mere exposure and bandwagon effect. If everyone starts running, you should also start running; maybe someone saw a lion coming and running could save your life. You may not know why, but it’s wiser to ask questions later.
Your brain picks up clues from the environment – including your peers – and uses simple rules to quickly translate those signals into decisions: Go with the winner, follow the majority, copy your neighbor. These rules work remarkably well in typical situations because they are based on sound assumptions. For example, they assume that people often act rationally, it is unlikely that many are wrong, the past predicts the future, and so on.
Technology allows people to access signals from much larger numbers of other people, most of whom they do not know. Artificial intelligence applications make heavy use of these popularity or “engagement” signals, from selecting search engine results to recommending music and videos, and from suggesting friends to ranking posts on news feeds.
Not everything viral deserves to be
Our research shows that virtually all web technology platforms, such as social media and news recommendation systems, have a strong popularity bias. When applications are driven by cues like engagement rather than explicit search engine queries, popularity bias can lead to harmful unintended consequences.
Social media like Facebook, Instagram, Twitter, YouTube and TikTok rely heavily on AI algorithms to rank and recommend content. These algorithms take as input what you like, comment on and share – in other words, content you engage with. The goal of the algorithms is to maximize engagement by finding out what people like and ranking it at the top of their feeds.
A primer on the Facebook algorithm.
On the surface this seems reasonable. If people like credible news, expert opinions and fun videos, these algorithms should identify such high-quality content. But the wisdom of the crowds makes a key assumption here: that recommending what is popular will help high-quality content “bubble up.”
We tested this assumption by studying an algorithm that ranks items using a mix of quality and popularity. We found that in general, popularity bias is more likely to lower the overall quality of content. The reason is that engagement is not a reliable indicator of quality when few people have been exposed to an item. In these cases, engagement generates a noisy signal, and the algorithm is likely to amplify this initial noise. Once the popularity of a low-quality item is large enough, it will keep getting amplified.
Algorithms aren’t the only thing affected by engagement bias – it can affect people too. Evidence shows that information is transmitted via “complex contagion,” meaning the more times people are exposed to an idea online, the more likely they are to adopt and reshare it. When social media tells people an item is going viral, their cognitive biases kick in and translate into the irresistible urge to pay attention to it and share it.
Not-so-wise crowds
We recently ran an experiment using a news literacy app called Fakey. It is a game developed by our lab, which simulates a news feed like those of Facebook and Twitter. Players see a mix of current articles from fake news, junk science, hyperpartisan and conspiratorial sources, as well as mainstream sources. They get points for sharing or liking news from reliable sources and for flagging low-credibility articles for fact-checking.
We found that players are more likely to like or share and less likely to flag articles from low-credibility sources when players can see that many other users have engaged with those articles. Exposure to the engagement metrics thus creates a vulnerability.
The wisdom of the crowds fails because it is built on the false assumption that the crowd is made up of diverse, independent sources. There may be several reasons this is not the case.
First, because of people’s tendency to associate with similar people, their online neighborhoods are not very diverse. The ease with which social media users can unfriend those with whom they disagree pushes people into homogeneous communities, often referred to as echo chambers.
Second, because many people’s friends are friends of one another, they influence one another. A famous experiment demonstrated that knowing what music your friends like affects your own stated preferences. Your social desire to conform distorts your independent judgment.
Third, popularity signals can be gamed. Over the years, search engines have developed sophisticated techniques to counter so-called “link farms” and other schemes to manipulate search algorithms. Social media platforms, on the other hand, are just beginning to learn about their own vulnerabilities.
A different, preventive approach would be to add friction. In other words, to slow down the process of spreading information. High-frequency behaviors such as automated liking and sharing could be inhibited by CAPTCHA tests or fees. Not only would this decrease opportunities for manipulation, but with less information people would be able to pay more attention to what they see. It would leave less room for engagement bias to affect people’s decisions.
It would also help if social media companies adjusted their algorithms to rely less on engagement to determine the content they serve you. Perhaps the revelations of Facebook’s knowledge of troll farms exploiting engagement will provide the necessary impetus.
Within seconds after reaching a city, earthquakes can cause immense destruction: Houses crumble, high-rises turn to rubble, people and animals are buried in the debris.
In the immediate aftermath of such carnage, emergency personnel desperately search for any sign of life in what used to be a home or office. Often, however, they find that they were digging in the wrong pile of rubble, and precious time has passed.
Imagine if rescuers could see through the debris to spot survivors under the rubble, measure their vital signs and even generate images of the victims. This is rapidly becoming possible using see-through-wall radar technology. Early versions of the technology that indicate whether a person is present in a room have been in use for several years, and some can measure vital signs albeit under better conditions than through rubble.
I’m an electrical engineer who researches electromagnetic communication and imaging systems. I and others are using fast computers, new algorithms and radar transceivers that collect large amounts of data to enable something much closer to the X-ray vision of science fiction and comic books. This emerging technology will make it possible to determine how many occupants are present behind a wall or barrier, where they are, what items they might be carrying and, in policing or military uses, even what type of body armor they might be wearing.
These see-through-wall radars will also be able to track individuals’ movements, and heart and respiration rates. The technology could also be used to determine from a distance the entire layout of a building, down to the location of pipes and wires within the walls, and detect hidden weapons and booby traps.
See-through-wall technology has been under development since the Cold War as a way to replace drilling holes through walls for spying. There are a few commercial products on the market today, like Range-R radar, that are used by law enforcement officers to track motion behind walls.
How radar works
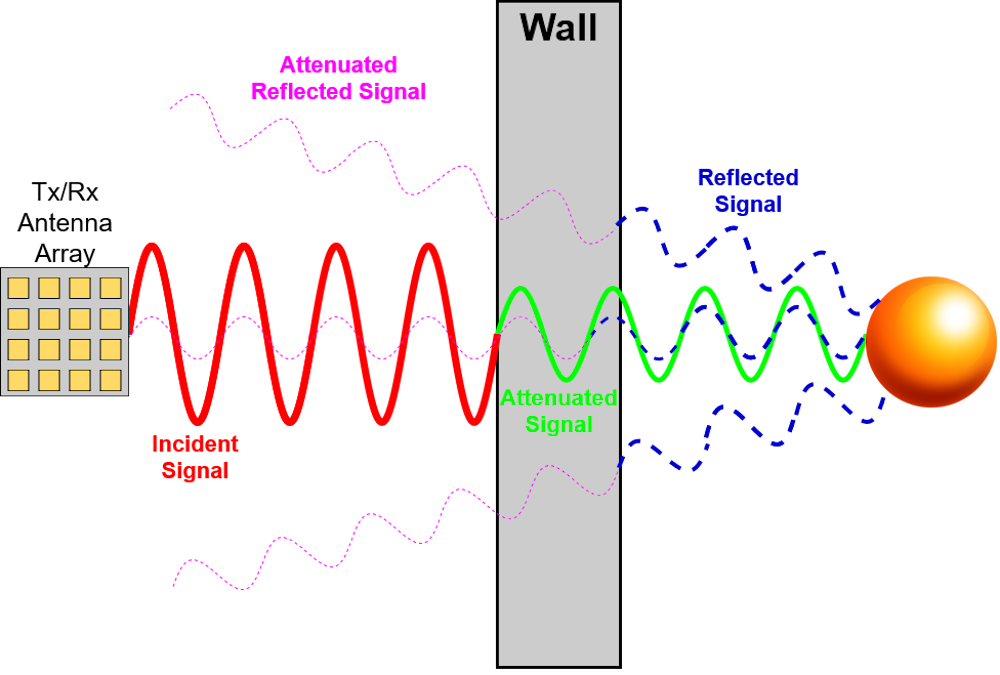
Radar stands for radio detection and ranging. Using radio waves, a radar sends a signal that travels at the speed of light. If the signal hits an object like a plane, for example, it is reflected back toward a receiver and an echo is seen in the radar’s screen after a certain time delay. This echo can then be used to estimate the location of the object.
In 1842, Christian Doppler, an Austrian physicist, described a phenomenon now known as the Doppler effect or Doppler shift, where the change in frequency of a signal is related to the speed and direction of the source of the signal. In Doppler’s original case, this was the light from a binary star system. This is similar to the changing pitch of a siren as an emergency vehicle speeds toward you, passes you and then moves away. Doppler radar uses this effect to compare the frequencies of the transmitted and reflected signals to determine the direction and speed of moving objects, like thunderstorms and speeding cars.
The Doppler effect can be used to detect tiny motions, including heartbeats and chest movement associated with breathing. In these examples, the Doppler radar sends a signal to a human body, and the reflected signal differs based on whether the person is inhaling or exhaling, or even based on the person’s heart rate. This allows the technology to accurately measure these vital signs.
How radar can go through walls
Like cellphones, radars use electromagnetic waves. When a wave hits solid walls like drywall or wood walls, a fraction of it is reflected off the surface. But the rest travels through the wall, especially at relatively low radio frequencies. The transmitted wave can be totally reflected back if it hits a metal object or even a human, because the human body’s high water content makes it highly reflective.
If the radar’s receiver is sensitive enough – a lot more sensitive than ordinary radar receivers – it can pick up the signals that are reflected back through the wall. Using well-established signal processing techniques, the reflections from static objects like walls and furniture can be filtered out, allowing the signal of interest – like a person’s location – to be isolated.
The key to using radar to track objects on the other side of a wall is having a very sensitive antenna that can pick up the greatly diminished reflected radio waves.Abdel-Kareem Moadi, CC BY-ND
Turning data into images
Historically, radar technology has been limited in its ability to aid in disaster management and law enforcement because it hasn’t had sufficient computational power or speed to filter out background noise from complicated environments like foliage or rubble and produce live images.
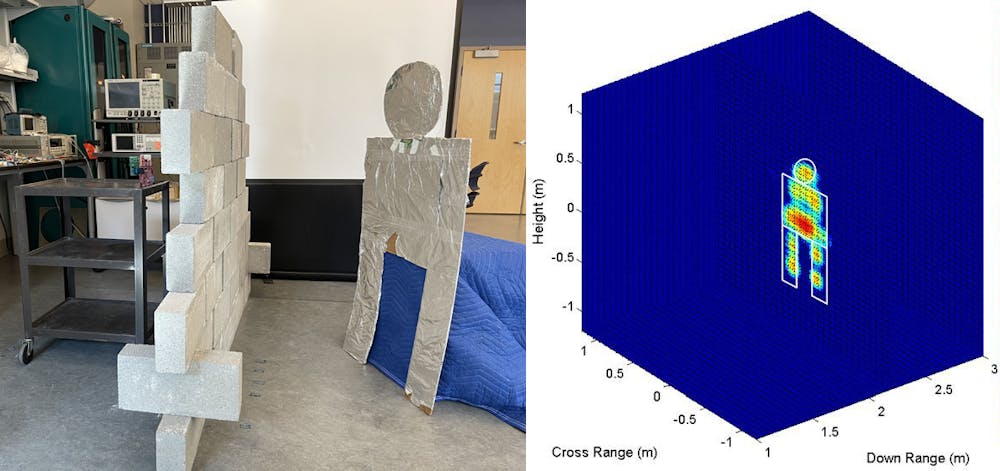
Today, however, radar sensors can often collect and process large amounts of data – even in harsh environments – and generate high-resolution images of targets. By using sophisticated algorithms, they can display the data in near real-time. This requires fast computer processors to rapidly handle these large amounts of data, and wideband circuits that can rapidly transmit data to improve the images’ resolution.
Recent developments in millimeter wave wireless technology, from 5G to 5G+ and beyond, are likely to help further improve this technology, providing higher-resolution images through order-of-magnitude wider bandwidth. The wireless technology will also speed data processing times because it greatly reduces latency, the time between transmitting and receiving data.
My laboratory is developing fast methods to remotely characterize the electrical characteristics of walls, which help in calibrating the radar waves and optimize the antennas to make the waves more easily pass through the wall and essentially make the wall transparent to the waves. We are also developing the software and hardware system to carry out the radar systems’ big data analyses in near real-time.
This laboratory wall-penetrating radar provides more detail than today’s commercial systems.Aly Fathy
Better electronics promise portable radars
Radar systems at the low frequencies usually required to see through walls are bulky due to the large size of the antenna. The wavelength of electromagnetic signals corresponds to the size of the antenna. Scientists have been pushing see-through-wall radar technology to higher frequencies in order to build smaller and more portable systems.
In addition to providing a tool for emergency services, law enforcement and the military, the technology could also be used to monitor the elderly and read vital signs of patients with infectious diseases like COVID-19 from outside a hospital room.
One indication of see-through-wall radar’s potential is the U.S. Army’s interest. They’re looking for technology that can create three-dimensional maps of buildings and their occupants in almost real-time. They are even looking for see-through-wall radar that can create images of people’s faces that are accurate enough for facial recognition systems to identify the people behind the wall.
Whether or not researchers can develop see-through-wall radar that’s sensitive enough to distinguish people by their faces, the technology is likely to move well beyond blobs on a screen to give first responders something like superhuman powers.
Texas A&M’s Robin Murphy has deployed robots at 29 disasters, including three building collapses, two mine disasters and an earthquake as director of the Center for Robot-Assisted Search and Rescue. She has also served as a technical search specialist with the Hillsboro County (Florida) Fire and Rescue Department. The Conversation talked to Murphy to provide readers an understanding of the types of technologies that search and rescue crews at the Champlain Towers South disaster site in Surfside, Florida, have at their disposal, as well as some they don’t. The interview has been edited for length.
What types of technologies are rescuers using at the Surfside condo collapse site?
We don’t have reports about it from Miami-Dade Fire Rescue Department, but news coverage shows that they’re using drones.
A standard kit for a technical search specialist would be basically a backpack of tools for searching the interior of the rubble: listening devices and a camera-on-a-wand or borescope for looking into the rubble.
How are drones typically used to help searchers?
They’re used to get a view from above to map the disaster and help plan the search, answering questions like: What does the site look like? Where is everybody? Oh crap, there’s smoke. Where is it coming from? Can we figure out what that part of the rubble looks like?
In Surfside, I wouldn’t be surprised if they were also flying up to look at those balconies that are still intact and the parts that are hanging over. A structural specialist with binoculars generally can’t see accurately above three stories. So they don’t have a lot of ability to determine if a building’s safe for people to be near, to be working around or in, by looking from the ground.
Search and rescue personnel use a drone to inspect the upper floors of the remaining portion of the Champlain Towers South Condo building.AP Photo/Wilfredo Lee
Drones can take a series of photos to generate orthomosaics. Orthomosaics are like those maps of Mars where they use software to glue all the individual photos together and it’s a complete map of the planet. You can imagine how useful an orthomosaic can be for dividing up an area for a search and seeing the progress of the search and rescue effort.
Search and rescue teams can use that same data for a digital elevation map. That’s software that gets the topology of the rubble and you can start actually measuring how high the pile is, how thick that slab is, that this piece of rubble must have come from this part of the building, and those sorts of things.
How might ground robots be used in this type of disaster?
The current state of the practice for searching the interior of rubble is to use either a small tracked vehicle, such as an Inkutun VGTV Extreme, which is the most commonly used robot for such situations, or a snakelike robot, such as the Active Scope Camera developed in Japan.
Teledyne FLIR is sending a couple of tracked robots and operators to the site in Surfside, Florida.
Ground robots are typically used to go into places that searchers can’t fit into and go farther than search cameras can. Search cams typically max out at 18 feet, whereas ground robots have been able to go over 60 feet into rubble. They are also used to go into unsafe voids that a rescuer could fit in but that would be unsafe and thus would require teams to work for hours to shore up before anyone could enter it safely.
In theory, ground robots could also be used to allow medical personnel to see and talk with survivors trapped in rubble, and carry small packages of water and medicine to them. But so far no search and rescue teams anywhere have found anyone alive with a ground robot.
What are the challenges for using ground robots inside rubble?
The big problem is seeing inside the rubble. You’ve got basically a concrete, sheetrock, piping and furniture version of pickup sticks. If you can get a robot into the rubble, then the structural engineers can see the interior of that pile of pickup sticks and say “Oh, OK, we’re not going pull on that, that’s going to cause a secondary collapse. OK, we should start on this side, we’ll get through the debris quicker and safer.”
Going inside rubble piles is really hard. Scale is important. If the void spaces are on the order of the size of the robot, it’s tricky. If something goes wrong, it can’t turn around; it has to drive backward. Tortuosity – how many turns per meter – is also important. The more turns, the harder it is.
There’s also different surfaces. The robot may be on a concrete floor, next thing it’s on a patch of somebody’s shag carpeting. Then it’s got to go through a bunch of concrete that’s been pulverized into sand. There’s dust kicking up. The surroundings may be wet from all the sewage and all the water from sprinkler systems and the sand and dust start acting like mud. So it gets really hard really fast in terms of mobility.
The author’s work includes putting robots through their paces at Texas A&M’s ‘Disaster City,’ a training facility with full-scale mockups of disaster sites including collapsed buildings.
What is your current research focus?
We look at human-robot interaction. We discovered that of all of the robots we could find in use, including ours – and we were the leading group in deploying robots in disasters – 51% of the failures during a disaster deployment were due to human error.
It’s challenging to work in these environments. I’ve never been in a disaster where there wasn’t some sort of surprise related to perception, something that you didn’t realize you needed to look for until you’re there.
What is your ideal search and rescue robot?
I’d like someone to develop a robot ferret. Ferrets are kind of snakey-looking mammals. But they have legs, small little legs. They can scoot around like a snake. They can claw with their little feet and climb up on uneven rocks. They can do a full meerkat, meaning they can stretch up really high and look around. They’re really good at balance, so they don’t fall over. They can be looking up and all of a sudden the ground starts to shift and they’re down and they’re gone – they’re fast.
How do you see the field of search and rescue robots going forward?
There’s no real funding for these types of ground robots. So there’s no economic incentive to develop robots for building collapses, which are very rare, thank goodness.
And the public safety agencies can’t afford them. They typically cost US$50,000 to $150,000 versus as little as $1,000 for an aerial drone. So the cost-benefit doesn’t seem to be there.
I’m very frustrated with this. We’re still about the same level we were 20 years ago at the World Trade Center.
Robin R. Murphy, Raytheon Professor of Computer Science and Engineering; Vice-President Center for Robot-Assisted Search and Rescue (nfp), Texas A&M University